To the 50th anniversary of the discovery of the structure of DNA
A.V. Zelenin
PLANT GENOME
A. V. Zelenin
Zelenin Alexander Vladimirovich- d.b.n.,
head of the laboratory of the Institute of Molecular Biology. V.A. Engelhardt RAS.
The impressive achievements of the "Human Genome" program, as well as the success of work on deciphering the so-called extra small (viruses), small (bacteria, yeast) and medium ( roundworm, Drosophila) genomes made possible the transition to a large-scale study of large and extra-large plant genomes. The urgent need for a detailed study of the genomes of the most economically important plants was emphasized at a meeting on plant genomics held in 1997 in the United States [ , ]. Over the years that have passed since that time, undoubted successes have been achieved in this area. In 2000, a publication appeared on the complete sequencing (determination of the linear nucleotide sequence of the entire nuclear DNA) of the genome of the small mustard - Arabidopsis, in 2001 - on the preliminary (draft) sequencing of the rice genome. Works on the sequencing of large and super-large plant genomes (corn, rye, wheat) were repeatedly reported, however, these reports did not contain specific information and were rather in the nature of declarations of intent.
It is assumed that the decoding of plant genomes will open up broad prospects for science and practice. First of all, the identification of new genes and the chain of their genetic regulation will significantly increase plant productivity through the use of biotechnological approaches. With the discovery, isolation, reproduction (cloning) and sequencing of genes responsible for such important functions of the plant organism as reproduction and productivity, the processes of variability, resistance to adverse environmental factors, as well as homologous pairing of chromosomes, the emergence of new opportunities for improving the breeding process is associated . Finally, isolated and cloned genes can be used to obtain transgenic plants with fundamentally new properties and to analyze the mechanisms of regulation of gene activity.
The importance of studying plant genomes is also emphasized by the fact that so far the number of localized, cloned and sequenced plant genes is small and varies, according to various estimates, between 800 and 1200. This is 10-15 times less than, for example, in humans.
The United States remains the undoubted leader in the large-scale study of plant genomes, although intensive studies of the rice genome are being carried out in Japan, and in last years and in China. In deciphering the genome of Arabidopsis, in addition to US laboratories, European research groups took an active part. The apparent leadership of the United States causes serious concern of European scientists, which they clearly expressed at a meeting under the significant title "Prospects for genomics in the post-genomic era", held in late 2000 in France. The advance of American science in studying the genomes of agricultural plants and creating transgenic plant forms, according to European scientists, threatens that in the not too distant future (two to five decades), when population growth will put humanity in the face of a general food crisis, the European economy and science will become dependent on American technology. In this regard, the creation of a Franco-German scientific program for the study of plant genomes ("Plantgene") was announced and significant investments were made in it.
Obviously, the problems of plant genomics should attract the close attention of Russian scientists and organizers of science, as well as the governing bodies, since it is not only about scientific prestige, but also about the national security of the country. In a decade or two, food will become the most important strategic resource.
DIFFICULTIES IN STUDYING PLANT GENOMES
The study of plant genomes is a much more difficult task than the study of the genome of humans and other animals. This is due to the following circumstances:
huge genome sizes, reaching tens and even hundreds of billions of base pairs (bp) for individual plant species: the genomes of the main economically important plants (except for rice, flax and cotton) are either close in size to the human genome, or exceed it many times (table);CHROMOSOMAL STUDIES OF GENOMESSharp fluctuations in the number of chromosomes in different plants - from two in some species to several hundred in others, and it is not possible to identify a strict correlation between the size of the genome and the number of chromosomes;
An abundance of polyploid (containing more than two genomes per cell) forms with similar but not identical genomes (alpolyploidy);
Extreme enrichment of plant genomes (up to 99%) of "insignificant" (non-coding, that is, not containing genes) DNA, which makes it very difficult for the sequenced fragments to join (arrange in the correct order) into a common large-sized DNA region (contig);
Incomplete (compared to the Drosophila, human and mouse genomes) morphological, genetic and physical mapping of chromosomes;
The practical impossibility of isolating individual chromosomes in pure form using methods usually used for this purpose for human and animal chromosomes (sorting in a stream and the use of cell hybrids);
Difficulty in chromosomal mapping (determining the location on the chromosome) individual genes through hybridization. in situ, due to both the high content of "insignificant" DNA in plant genomes, and the peculiarities of the structural organization of plant chromosomes;
The evolutionary remoteness of plants from animals, which seriously complicates the use of information obtained by sequencing the genomes of humans and other animals for the study of plant genomes;
The long process of reproduction of most plants, which significantly slows down their genetic analysis.
Chromosomal (cytogenetic) studies of genomes in general and plants in particular have a long history. The term "genome" was proposed to refer to a haploid (single) set of chromosomes with the genes contained in them in the first quarter of the 20th century, that is, long before the establishment of the role of DNA as a carrier of genetic information.
The description of the genome of a new, previously genetically unstudied multicellular organism usually begins with the study and description of the complete set of its chromosomes (karyotype). This, of course, also applies to plants, a huge number of which have not even begun to be studied.
Already at the dawn of chromosome studies, the genomes of related plant species were compared based on the analysis of meiotic conjugation (combination of homologous chromosomes) in interspecific hybrids. Over the past 100 years, the possibilities of chromosome analysis have expanded dramatically. Now, more advanced technologies are used to characterize plant genomes: various variants of the so-called differential staining, which allows one to morphological features identify individual chromosomes; hybridization in situ making it possible to localize specific genes on chromosomes; biochemical studies of cellular proteins (electrophoresis and immunochemistry) and, finally, a set of methods based on the analysis of chromosomal DNA up to its sequencing.

Rice. one. Cereal karyotypes a - rye (14 chromosomes), b - durum wheat (28 chromosomes), c - soft wheat (42 chromosomes), d - barley (14 chromosomes)For many years, the karyotypes of cereals, primarily wheat and rye, have been studied. Interestingly, in different species of these plants, the number of chromosomes is different, but always a multiple of seven. Individual types of cereals can be reliably recognized by their karyotype. For example, the rye genome consists of seven pairs of large chromosomes with intensely colored heterochromatic blocks at their ends, often called segments or bands (Fig. 1a). Wheat genomes already have 14 and 21 pairs of chromosomes (Fig. 1, b, c), and the distribution of heterochromatic blocks in them is not the same as in rye chromosomes. Individual wheat genomes, designated A, B and D, also differ from each other. An increase in the number of chromosomes from 14 to 21 leads to a sharp change in the properties of wheat, which is reflected in their names: durum, or pasta, wheat and soft, or bread, wheat . The D gene, which contains genes for gluten proteins, which gives the dough the so-called germination, is responsible for the acquisition of high baking properties by soft wheat. It is this genome that is given special attention in the selection improvement of bread wheat. Another 14-chromosome cereal, barley (Fig. 1, d), is not usually used to make bread, but it is the main raw material for the manufacture of such common products as beer and whiskey.
The chromosomes of some wild plants used to improve the quality of the most important agricultural species, such as the wild relatives of wheat - Aegilops, are being intensively studied. New plant forms are created by crossing (Fig. 2) and selection. In recent years, a significant improvement in research methods has made it possible to begin the study of plant genomes, the features of the karyotypes of which (mainly the small size of chromosomes) made them previously inaccessible for chromosome analysis. So, only recently all the chromosomes of cotton, chamomile and flax were identified for the first time.

Rice. 2. Karyotypes of wheat and a hybrid of wheat with Aegilops
a - hexaploid soft wheat ( Triticum astivum), consisting of A, B and O genomes; b - tetraploid wheat ( Triticum timopheevi), consisting of A and G genomes. contains genes for resistance to most wheat diseases; c - hybrids Triticum astivum X Triticum timopheevi resistant to powdery mildew and rust, the replacement of part of the chromosomes is clearly visiblePRIMARY STRUCTURE OF DNA
With the development of molecular genetics, the very concept of the genome has expanded. Now this term is interpreted both in the classical chromosomal and in the modern molecular sense: the entire genetic material of an individual virus, cell and organism. Naturally, following the study of the complete primary structure of the genomes (as the complete linear sequence of nucleic acid bases is often called) of a number of microorganisms and humans, the question of plant genome sequencing arose.
Of the many plant organisms, two were selected for study - Arabidopsis, representing the class of dicots (genome size 125 million bp), and rice from the class of monocots (420-470 million bp). These genomes are small compared to other plant genomes and contain relatively few repetitive DNA segments. Such features gave hope that the selected genomes would be available for relatively rapid determination of their primary structure.

Rice. 3. Arabidopsis - small mustard - a small plant from the cruciferous family ( Brassicaceae). On a space equal in area to one page of our magazine, you can grow up to a thousand individual Arabidopsis organisms.The reason for choosing Arabidopsis was not only the small size of its genome, but also the small size of the organism, which makes it easy to grow it in the laboratory (Fig. 3). We took into account its short reproductive cycle, thanks to which it is possible to quickly conduct experiments on crossing and selection, genetics studied in detail, ease of manipulation with changing growing conditions (changing the salt composition of the soil, adding various nutrients, etc.) and testing the effect on plants of various mutagenic factors and pathogens (viruses, bacteria, fungi). Arabidopsis has no economic value, therefore, its genome, along with the mouse genome, was called a reference, or, less accurately, a model.*
* The appearance of the term "model genome" in Russian literature is the result of an inaccurate translation of the English phrase model genome. The word "model" means not only the adjective "model", but also the noun "sample", "standard", "model". It would be more correct to speak of a sample genome, or a reference genome.Intensive work on Arabidopsis genome sequencing was started in 1996 by an international consortium that included scientific institutions and research groups from the USA, Japan, Belgium, Italy, Great Britain, and Germany. In December 2000, extensive information became available summarizing the determination of the primary structure of the Arabidopsis genome. Classical or hierarchical technology was used for sequencing: first, individual small sections of the genome were studied, from which larger sections (contigs) were composed, and, at the final stage, the structure of individual chromosomes. The nuclear DNA of the Arabidopsis genome is distributed over five chromosomes. In 1999, the results of sequencing of two chromosomes were published, and the appearance in the press of information about the primary structure of the remaining three completed the sequencing of the entire genome.
Out of 125 million base pairs, the primary structure of 119 million has been determined, which is 92% of the entire genome. Only 8% of the Arabidopsis genome containing large blocks of repetitive DNA segments turned out to be inaccessible for study. In terms of the completeness and thoroughness of eukaryotic genome sequencing, Arabidopsis remains in the top three champions along with a unicellular yeast organism. Saccharomyces cerevisiae and multicellular organism Caenorhabditis elegance(see table).
About 15,000 individual protein-coding genes have been found in the Arabidopsis genome. Approximately 12,000 of these are contained as two copies per haploid (single) genome, so that total number genes is 27 thousand. The number of genes in Arabidopsis does not differ much from the number of genes in organisms such as humans and mice, but the size of its genome is 25-30 times smaller. This circumstance is associated with important features in the structure of individual Arabidopsis genes and the overall structure of its genome.
Arabidopsis genes are compact, containing only a few exons (protein-coding regions) separated by short (about 250 bp) non-coding DNA segments (introns). The intervals between individual genes are on average 4600 base pairs. For comparison, we point out that human genes contain many tens and even hundreds of exons and introns, and intergenic regions have sizes of 10 thousand base pairs or more. It is assumed that the presence of a small compact genome contributed to the evolutionary stability of Arabidopsis, since its DNA became a target for various damaging agents to a lesser extent, in particular, for the introduction of virus-like repetitive DNA fragments (transposons) into the genome.
Among other molecular features of the Arabidopsis genome, it should be noted that exons are enriched in guanine and cytosine (44% in exons and 32% in introns) compared with animal genes, as well as the presence of doubly repeated (duplicated) genes. It is assumed that such a doubling occurred as a result of four simultaneous events, consisting in the doubling (repetition) of a part of the Arabidopsis genes, or the fusion of related genomes. These events, which took place 100-200 million years ago, are a manifestation of the general trend towards polyploidization (a multiple increase in the number of genomes in an organism), which is characteristic of plant genomes. However, some facts show that duplicated genes in Arabidopsis are not identical and function differently, which may be associated with mutations in their regulatory regions.
Rice has become another object of complete DNA sequencing. The genome of this plant is also small (12 chromosomes, giving a total of 420-470 million bp), only 3.5 times larger than that of Arabidopsis. However, unlike Arabidopsis, rice is of great economic importance, being the basis of nutrition for more than half of humanity, therefore, not only billions of consumers, but also a multimillion-strong army of people actively involved in the very laborious process of its cultivation are vitally interested in improving its properties.
Some researchers began to study the rice genome as early as the 1980s, but these studies reached a serious scale only in the 1990s. In 1991, a program was created in Japan to decipher the structure of the rice genome, bringing together the efforts of many research groups. In 1997, the International Rice Genome Project was organized on the basis of this program. Its participants decided to concentrate their efforts on sequencing one of the subspecies of rice ( Oriza sativajaponica), in the study of which significant progress had already been achieved by that time. A serious stimulus and, figuratively speaking, a guiding star for such work was the "Human Genome" program.
Within the framework of this program, the strategy of "chromosomal" hierarchical division of the genome was tested, which the participants of the international consortium used to decipher the rice genome. However, if the study of the human genome using various tricks fractions of individual chromosomes were isolated, then the material specific for individual chromosomes of rice and their individual sections was obtained by laser microdissection (cutting out microscopic objects). On a microscope slide, where rice chromosomes are located, under the influence of a laser beam, everything is burned out, except for the chromosome or its sections scheduled for analysis. The remaining material is used for cloning and sequencing.
Numerous reports have been published on the results of sequencing of individual fragments of the rice genome, carried out with high accuracy and detail, characteristic of hierarchical technology. It was believed that the determination of the complete primary structure of the rice genome would be completed by the end of 2003–mid 2004, and the results, together with data on the primary structure of the Arabidopsis genome, would be widely used in the comparative genomics of other plants.
However, in early 2002, two research groups - one from China, the other from Switzerland and the United States - published the results of a complete draft (approximate) sequencing of the rice genome, performed using total cloning technology. In contrast to the staged (hierarchical) study, the total approach is based on the simultaneous cloning of the entire genomic DNA in one of the viral or bacterial vectors and obtaining a significant (huge for medium and large genomes) number of individual clones containing various DNA segments. Based on the analysis of these sequenced sections and the overlapping of identical terminal sections of DNA, a contig is formed - a chain of DNA sequences joined together. The general (total) contig is the primary structure of the entire genome, or at least of an individual chromosome.
In such a schematic presentation, the strategy of total cloning seems simple. In fact, it encounters serious difficulties associated with the need to obtain a huge number of clones (it is generally accepted that the genome or its region under study must be overlapped by clones at least 10 times), the huge amount of sequencing and the extremely complex work of docking clones that require participation bioinformatics specialists. A serious obstacle to total cloning is a variety of repetitive DNA segments, the number of which, as already mentioned, increases sharply as the size of the genome increases. Therefore, the strategy of total sequencing is mainly used in the study of the genomes of viruses and microorganisms, although it has been successfully used to study the genome of a multicellular organism, Drosophila.
The results of the total sequencing of this genome were "superimposed" on a huge array of information about its chromosomal, gene, and molecular structure, obtained over an almost 100-year period of study of Drosophila. And yet, in terms of the degree of sequencing, the Drosophila genome (66% of the total genome size) is significantly inferior to the Arabidopsis genome (92%), despite their rather close sizes - 180 million and 125 million base pairs, respectively. Therefore, it has recently been proposed to name the mixed technology, which was used for sequencing the Drosophila genome.
To sequence the genome of rice, the research groups mentioned above took two of its subspecies, the most widely cultivated in Asian countries, - Oriza saliva L. ssp indicaj and Oriza saliva L. sspjaponica. The results of their studies coincide in many respects, but differ in many respects. Thus, the representatives of both groups stated that they had reached approximately 92-93% of the genome overlap with contigs. It has been shown that about 42% of the rice genome is represented by short DNA repeats consisting of 20 base pairs, and most of the mobile DNA elements (transposons) are located in intergenic regions. However, data on the size of the rice genome differ significantly.
For the Japanese subspecies, the genome size is determined to be 466 million base pairs, and for the Indian subspecies, 420 million. The reason for this discrepancy is not clear. It may be the result of various methodological approaches in determining the size of the non-coding part of the genomes, that is, do not reflect the true state of affairs. But it is possible that a 15% difference in the size of the studied genomes does exist.
The second major discrepancy was revealed in the number of genes found: for the Japanese subspecies, from 46,022 to 55,615 genes per genome, and for the Indian subspecies, from 32,000 to 50,000. The reason for this discrepancy is not clear.
The incompleteness and inconsistency of the information received is noted in the comments to the published articles. The hope is also expressed here that gaps in knowledge of the rice genome will be eliminated by comparing the data of "rough sequencing" with the results of detailed, hierarchical sequencing carried out by the participants of the International Rice Genome Project.
COMPARATIVE AND FUNCTIONAL PLANT GENOMICS
The extensive data obtained, half of which (the results of the Chinese group) are publicly available, undoubtedly open up broad prospects for both the study of the rice genome and plant genomics in general. A comparison of the properties of Arabidopsis and rice genomes showed that most of the genes (up to 80%) identified in the Arabidopsis genome are also found in the rice genome, however, for approximately half of the genes found in rice, analogues (orthologs) have not yet been found in the Arabidopsis genome. . At the same time, 98% of the genes whose primary structure has been established for other cereals were found in the rice genome.
The significant (almost twofold) discrepancy between the number of genes in rice and Arabidopsis is puzzling. At the same time, the data of the draft decoding of the rice genome, obtained using total sequencing, are practically not compared with the extensive results of the study of the rice genome by the method of hierarchical cloning and sequencing, that is, what has been done with respect to the Drosophila genome has not been carried out. Therefore, it remains unclear whether the difference in the number of genes in Arabidopsis and rice reflects the true state of affairs or whether it is explained by the difference in methodological approaches.
In contrast to the genome of Arabidopsis, data on twin genes in the rice genome are not given. It is possible that their relative amount may be higher in rice than in Arabidopsis. This possibility is indirectly supported by data on the presence of polyploid forms of rice. More clarity on this issue can be expected after the International Rice Genome Project is completed and a detailed picture of the primary DNA structure of this genome is obtained. Serious grounds for such a hope are provided by the fact that after the publication of works on the rough sequencing of the rice genome, the number of publications on the structure of this genome has sharply increased, in particular, information has appeared on the detailed sequencing of its 1 and 4 chromosomes.
Knowing, at least approximately, the number of genes in plants is of fundamental importance for comparative plant genomics. Initially, it was believed that since all flowering plants are very close to each other in terms of their phenotypic characteristics, their genomes should also be similar. And if we study the genome of Arabidopsis, we will get information about most of the genomes of other plants. An indirect confirmation of this assumption is the results of sequencing of the mouse genome, which is surprisingly close to the human genome (about 30 thousand genes, of which only 1 thousand turned out to be different).
It can be assumed that the reason for the differences between the genomes of Arabidopsis and rice lies in their belonging to different classes of plants - dicots and monocots. To clarify this issue, it is highly desirable to know at least a rough primary structure of some other monocotyledonous plant. The most realistic candidate could be corn, whose genome is approximately equal to the human genome, but still much smaller than the genomes of other cereals. The nutritional value of corn is well known.
The vast material obtained as a result of sequencing the Arabidopsis and rice genomes is gradually becoming the basis for a large-scale study of plant genomes using comparative genomics. Such studies are of general biological significance, since they make it possible to establish the main principles of the organization of the plant genome as a whole and their individual chromosomes, to identify common features of the structure of genes and their regulatory regions, and to consider the ratio of the functionally active (gene) part of the chromosome and various intergenic DNA regions that do not code for proteins. Comparative genetics is also becoming increasingly important for the development of human functional genomics. It is for comparative studies that sequencing of the pufferfish and mouse genomes was carried out.
Equally important is the study of individual genes responsible for the synthesis of individual proteins that determine specific body functions. It is in the discovery, isolation, sequencing and determination of the function of individual genes that the practical, primarily medical, significance of the Human Genome program lies. This circumstance was noted several years ago by J. Watson, who emphasized that the Human Genome program would be completed only when the functions of all human genes were determined.
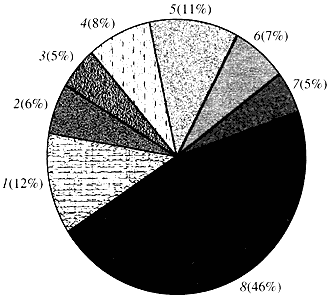
Rice. 4. Classification according to the function of Arabidopsis genes
1 - genes for growth, division and DNA synthesis; 2 - RNA synthesis genes (transcription); 3 - genes for the synthesis and modification of proteins; 4 - genes for development, aging and cell death; 5 - genes for cell metabolism and energy metabolism; 6 - genes of intercellular interaction and signal transmission; 7 - genes for providing others cellular processes; 8 - genes with unknown functionAs for the function of plant genes, we know less than one-tenth of what we know about human genes. Even in Arabidopsis, whose genome is much more studied than the human genome, the function of almost half of its genes remains unknown (Fig. 4). Meanwhile, in addition to genes common with animals, plants have a significant number of genes that are specific only (or at least predominantly) for them. It's about about the genes involved in the transport of water and the synthesis of the cell wall, which is absent in animals, about the genes that ensure the formation and functioning of chloroplasts, photosynthesis, nitrogen fixation and the synthesis of numerous aromatic products. This list can be continued, but it is already clear what a difficult task the functional genomics of plants faces.
Full genome sequencing provides close to true information about the total number of genes in a given organism, makes it possible to place more or less detailed and reliable information about their structure in data banks, and facilitates the work of isolating and studying individual genes. However, genome sequencing by no means means establishing the function of all genes.
One of the most promising approaches of functional genomics is based on the identification of working genes that are used for transcription (reading) of mRNA. This approach, including modern technology microarrays, allows you to simultaneously identify up to tens of thousands of functioning genes. Recently, using this approach, the study of plant genomes has begun. For Arabidopsis, it was possible to obtain about 26 thousand individual transcripts, which greatly facilitates the possibility of determining the function of almost all of its genes. In potatoes, it was possible to identify about 20,000 working genes that are important for understanding both the processes of growth and tuber formation, and the processes of potato disease. It is expected that this knowledge will improve the sustainability of one of the most important food products to pathogens.
The logical development of functional genomics was proteomics. This new field of science studies the proteome, which is usually understood as the complete set of proteins in a cell at a particular moment. Such a set of proteins, reflecting the functional state of the genome, changes all the time, while the genome remains unchanged.
The study of proteins has long been used to judge the activity of plant genomes. As is known, the enzymes present in all plants differ in individual species and varieties in the sequence of amino acids. Such enzymes, with the same function, but a different sequence of individual amino acids, are called isoenzymes. They have different physicochemical and immunological properties ( molecular mass, charge), which can be detected using chromatography or electrophoresis. For many years, these methods have been successfully used to study the so-called genetic polymorphism, that is, the differences between organisms, varieties, populations, species, in particular wheat and related forms of cereals. Recently, however, due to the rapid development of DNA analysis methods, including sequencing, the study of protein polymorphism has been replaced by the study of DNA polymorphism. However, direct study of the spectra of storage proteins (prolamins, gliadins, etc.), which determine the main nutritional properties of cereals, remains an important and reliable method for genetic analysis, selection, and seed production of agricultural plants.
Knowledge of genes, the mechanisms of their expression and regulation is extremely important for the development of biotechnology and the production of transgenic plants. It is known that the impressive successes in this area cause an ambiguous reaction from the environmental and medical community. However, there is an area of plant biotechnology where these fears, if not completely unfounded, then, in any case, seem to be of little importance. We are talking about the creation of transgenic industrial plants that are not used as food products. India recently harvested the first crop of transgenic cotton that is resistant to a number of diseases. There is information about the introduction of special genes encoding pigment proteins into the cotton genome and the production of cotton fibers that do not require artificial dyeing. Another industrial crop that may be the object of effective genetic engineering is flax. Its use as an alternative to cotton for textile raw materials has been discussed recently. This problem is extremely important for our country, which has lost its own sources of raw cotton.
PROSPECTS FOR STUDYING PLANT GENOMES
Obviously, structural studies of plant genomes will be based on the approaches and methods of comparative genomics, using the results of deciphering the genomes of Arabidopsis and rice as the main material. An important role in the development of comparative plant genomics will undoubtedly be played by information that will sooner or later be provided by total (rough) sequencing of the genomes of other plants. In this case, comparative plant genomics will be based on the establishment of genetic relationships between individual loci and chromosomes belonging to different genomes. We will focus not so much on the general genomics of plants as on the selective genomics of individual chromosomal loci. For example, it has recently been shown that the gene responsible for vernalization is located at the VRn-AI locus of hexaploid wheat chromosome 5A and the Hd-6 locus of rice chromosome 3.
The development of these studies will be a powerful impetus for the identification, isolation, and sequencing of many functionally important plant genes, in particular, genes responsible for disease resistance, drought resistance, and adaptability to various growing conditions. Increasingly, functional genomics will be used, based on the mass detection (screening) of genes functioning in plants.
We can foresee further improvement of chromosomal technologies, primarily the microdissection method. Its use dramatically expands the possibilities of genomic research without requiring huge costs, such as, for example, total genome sequencing. The method of localization on the chromosomes of plants of individual genes with the help of hybridization will be further spread. in situ. Currently, its use is limited. huge number repetitive sequences in the plant genome, and, possibly, the features of the structural organization of plant chromosomes.
Chromosomal technologies will become of great importance for the evolutionary genomics of plants in the foreseeable future. These relatively inexpensive technologies make it possible to quickly assess intra- and interspecific variability, study complex allopolyploid genomes of tetraploid and hexaploid wheat, triticale; analyze evolutionary processes at the chromosomal level; investigate the formation of synthetic genomes and the introduction (introgression) of foreign genetic material; identify genetic relationships between individual chromosomes of different species.
The study of plant karyotype using classical cytogenetic methods, enriched by molecular biological analysis and computer technology, will be used to characterize the genome. This is especially important for studying the stability and variability of the karyotype at the level of not only individual organisms, but also populations, varieties, and species. Finally, it is difficult to imagine how the number and spectra of chromosomal rearrangements (aberrations, bridges) can be estimated without the use of differential staining methods. Such studies are extremely promising for monitoring environment according to the state of the plant genome.
In modern Russia, direct sequencing of plant genomes is unlikely to be carried out. Such work, which requires large investments, is beyond the strength of our current economy. Meanwhile, the data on the structure of the genomes of Arabidopsis and rice, obtained by world science and available in international data banks, are sufficient for the development of domestic plant genomics. One can foresee the expansion of studies of plant genomes based on comparative genomics approaches to solve specific problems of breeding and crop production, as well as to study the origin of various plant species of great economic importance.
It can be assumed that genomic approaches such as genetic typing (RELF, RAPD, AFLP analyzes, etc.), which are quite affordable for our budget, will be widely used in domestic breeding practice and crop production. In parallel with direct methods for determining DNA polymorphism, approaches based on the study of protein polymorphism, primarily storage proteins of cereals, will be used to solve the problems of genetics and plant breeding. Chromosomal technologies will be widely used. They are relatively inexpensive, their development requires quite moderate investments. In the field of chromosome studies, domestic science is not inferior to the world.
It should be emphasized that our science has made a significant contribution to the formation and development of plant genomics [ , ].
The fundamental role was played by N.I. Vavilov (1887-1943).
In molecular biology and plant genomics, the pioneering contribution of A.N. Belozersky (1905-1972).
In the field of chromosomal studies, it is necessary to note the work of the outstanding geneticist S.G. Navashin (1857-1930), who first discovered satellite chromosomes in plants and proved that it is possible to distinguish between individual chromosomes according to the features of their morphology.
Another classic of Russian science G.A. Levitsky (1878-1942) described in detail the chromosomes of rye, wheat, barley, peas and sugar beets, introduced the term "karyotype" into science and developed the doctrine of it.
Modern specialists, relying on the achievements of world science, can make a significant contribution to the further development of plant genetics and genomics.
The author expresses his heartfelt thanks to Academician Yu.P. Altukhov for critical discussion of the article and valuable advice.The work of the team headed by the author of the article was supported by Russian fund fundamental research (grants No. 99-04-48832; 00-04-49036; 00-04-81086), Program of the President Russian Federation for the support of scientific schools (grants No. 00-115-97833 and NSh-1794.2003.4) and the Program of the Russian Academy of Sciences "Molecular genetic and chromosomal markers in the development of modern methods of breeding and seed production".
LITERATURE
1. Zelenin A.V., Badaeva E.D., Muravenko O.V. Introduction to plant genomics // Molecular biology. 2001. V. 35. S. 339-348. 2. Pen E. Bonanza for Plant Genomics // Science. 1998. V. 282. P. 652-654. 3. Plant genomics, Proc. Natl. Acad. sci. USA. 1998. V. 95. P. 1962-2032. 4. Cartel N.A. and etc. Genetics. Encyclopedic Dictionary. Minsk: Technologia, 1999. 5. Badaeva E.D., Friebe B., Gill B.S. 1996. Genome differentiation in Aegilops. 1. Distribution of highly repetitive DNA sequences on chromosomes of diploid species, Genome. 1996. V. 39. P. 293-306. History of chromosome analysis // Biol. membranes. 2001. T. 18. S. 164-172.
It is a pandemic parasite that infects 70% of invertebrates worldwide and evolves with them. Most often, the parasite infects insects, while it penetrates their eggs and spermatozoa and is transmitted to offspring. This fact prompted scientists to assume that any resulting genetic changes are passed down from generation to generation.
This finding, led by scientists led by Jack Werren, indicates that horizontal (interspecific) gene transfer between bacteria and multicellular organisms occurs more often than is commonly believed, and leaves a certain imprint on the evolutionary process. Bacterial DNA can be a full-fledged part of the genome of an organism and even be responsible for the formation of certain traits - at least in invertebrates.
The likelihood that such a large piece of DNA is completely neutral is minimal, and experts believe that the genes contained in it provide insects with certain breeding advantages. The authors are currently in the process of identifying these benefits. Evolutionary biologists should pay close attention to this discovery.
Jumping genes
In the middle of the last century, American researcher Barbara McClintock discovered amazing genes in corn that can independently change their position on chromosomes. Now they are called "jumping genes" or transposable (mobile) elements. The discovery was not recognized for a long time, considering mobile elements to be a unique phenomenon, characteristic only for corn. However, it was for this discovery in 1983 that McClintock was awarded Nobel Prize Today, jumping genes have been found in almost all studied animal and plant species.
Where did the hopping genes come from, what do they do in the cell, are there any benefits from them? Why, with genetically healthy parents, the family of the Drosophila fruit fly, due to jumping genes, can produce mutant offspring with a high frequency or even be completely childless? What is the role of jumping genes in evolution?
It must be said that the genes that ensure the functioning of cells are located on the chromosomes in a certain order. Thanks to this, for many species of unicellular and multicellular organisms, it was possible to build so-called genetic maps. However, there is an order of magnitude more genetic material between genes than in themselves! What role this “ballast” part of DNA plays has not been fully established, but it is here that mobile elements are most often found, which not only move themselves, but can also take neighboring DNA fragments with them.

Where do jumper genes come from? It is believed that at least some of them originate from viruses, since some mobile elements are able to form viral particles (for example, the gipsy mobile element in the fruit fly Drosophila melanogaster). Some transposable elements appear in the genome by the so-called horizontal transfer from other types. For example, it is found that mobile hobo-element (translated into Russian, it is called a tramp) Drosophila melanogaster repeatedly introduced into the genome of this species. There is a version that some regulatory regions of DNA may also have autonomy and a tendency to "vagrancy".
useful ballast
On the other hand, most of the jumping genes, despite the name, behave quietly, although they make up a fifth of the total genetic material. Drosophila melanogaster or almost half of the human genome.
The redundancy of DNA, which was mentioned above, has its own plus: ballast DNA (including passive mobile elements) takes the hit if foreign DNA is introduced into the genome. The likelihood that a new element will be inserted into a useful gene and thereby disrupt its operation is reduced if there is much more bulky DNA than significant.
Some redundancy of DNA is useful in the same way as the "redundancy" of letters in words: we write "Maria Ivanovna" and say "Marivana". Some of the letters are inevitably lost, but the meaning remains. The same principle also works at the level of significance of individual amino acids in a protein-enzyme molecule: only the sequence of amino acids that forms the active center is strictly conservative. Thus, at different levels, redundancy turns out to be a kind of buffer that provides a safety margin for the system. This is how mobile elements that have lost their mobility are not useless for the genome. As they say, “from a thin sheep even a tuft of wool”, although, perhaps, another proverb would be better suited here - “each bast in a line”.

Mobile elements that have retained the ability to jump move along Drosophila chromosomes at a frequency of 10–2–10–5 per gene per generation, depending on the type of element, genetic background, and external conditions. This means that one out of a hundred jumping genes in a cell can change its position after the next cell division. As a result, after several generations, the distribution of transposable elements along the chromosome can change very significantly.
It is convenient to study such a distribution on polytene (multi-stranded) chromosomes from salivary glands Drosophila larvae. These chromosomes are many times thicker than normal ones, making it much easier to examine them under a microscope. How are these chromosomes made? In the cells of the salivary glands, the DNA of each of the chromosomes is multiplied, as in normal cell division, but the cell itself does not divide. As a result, the number of cells in the gland does not change, but in 10-11 cycles, several thousand identical DNA strands accumulate in each chromosome.

Partly because of the polytene chromosomes, jumping genes in Drosophila are better understood than in other metazoans. As a result of these studies, it turned out that even within the same Drosophila population it is difficult to find two individuals that have chromosomes with the same distribution of mobile elements. It is no coincidence that most of the spontaneous mutations in Drosophila are believed to be caused by the movement of these "hoppers".
Consequences may vary...
Based on their effect on the genome, active transposable elements can be divided into several groups. Some of them perform functions that are extremely important and useful for the genome. For example, telomeric DNA, located at the ends of chromosomes, in Drosophila just consists of special mobile elements. This DNA is extremely important - the loss of it entails the loss of the entire chromosome in the process of cell division, which leads to cell death.
Other mobile elements are outright "pests". At least they are considered as such this moment. For example, transposable elements of the R2 class can be specifically introduced into arthropod genes that encode one of the proteins of ribosomes - cellular "factories" for protein synthesis. Individuals with such disorders survive only because only a part of the many genes encoding these proteins is damaged in the genome.

There are also such mobile elements that move only in the reproductive tissues that produce germ cells. This is explained by the fact that in different tissues the same mobile element can produce different in length and functions of the protein-enzyme molecule necessary for movement.
An example of the latter is the P-element Drosophila melanogaster, which got into its natural populations by horizontal transfer from another species of Drosophila no more than a hundred years ago. However, there is hardly a population on Earth right now. Drosophila melanogaster, in which there would be no P-element. At the same time, it should be noted that most of its copies are defective, moreover, the same version of the defect was found almost everywhere. The role of the latter in the genome is peculiar: it is "intolerant" to its fellows and plays the role of a repressor, blocking their movement. So the protection of the Drosophila genome from the jumps of the "alien" can be partially carried out by its own derivatives.
The main thing is to choose the right parents!
Most of the jumps of mobile elements do not affect appearance Drosophila, because it falls on the ballast DNA, but there are other situations when their activity increases dramatically.

Oddly enough, the most powerful factor that induces the movement of jumping genes is poor parenting. For example, what happens if you cross females from a laboratory population Drosophila melanogaster, which do not have a P-element (because their ancestors were caught from nature about a hundred years ago), with males carrying a P-element? In hybrids, due to the rapid movement of the mobile element, a large number of various genetic disorders may appear. This phenomenon, called hybrid dysgenesis, is caused by the absence of a repressor in the maternal cytoplasm that prohibits the movement of the mobile element.
Thus, if grooms from population A and brides from population B can create large families, then the opposite is not always true. A family of genetically healthy parents can produce a large number of mutant or infertile offspring, or even be childless if the father and mother have a different set of mobile elements in the genome. Especially many violations appear if the experiment is carried out at a temperature of 29 ° C. The influence of external factors, superimposed on the genetic background, enhances the effect of genome mismatch, although these factors alone (even ionizing radiation) alone are not capable of causing such a massive movement of mobile elements.
Similar events in Drosophila melanogaster can occur with the participation of other families of mobile elements.
"Mobile" evolution
The cellular genome can be viewed as a kind of ecosystem of permanent and temporary members, where neighbors not only coexist, but also interact with each other. The interaction of host genes with transposable elements is still poorly understood, but many results can be cited - from the death of an organism in the event of damage to an important gene to the restoration of previously damaged functions.
It happens that the jumping genes themselves interact with each other. Thus, a phenomenon resembling immunity is known, when a mobile element cannot be introduced in the immediate vicinity of an existing one. However, not all mobile elements are so delicate: for example, P-elements can easily embed themselves into each other and take their brothers out of the game.

In addition, there is a kind of self-regulation of the number of transposable elements in the genome. The fact is that mobile elements can exchange homologous regions with each other - this process is called recombination. As a result of such interaction, mobile elements may, depending on their orientation, lose ( deletion) or expand ( inversion) fragments of host DNA located between them. If a significant piece of the chromosome is lost, the genome will die. In the case of an inversion or a small deletion, chromosome diversity is created, which is considered a necessary condition for evolution.
If recombinations occur between mobile elements located on different chromosomes, then chromosomal rearrangements are formed as a result, which, during subsequent cell divisions, can lead to an imbalance in the genome. And an unbalanced genome, like an unbalanced budget, is very poorly divided. So the death of unsuccessful genomes is one of the reasons why active transposable elements do not flood chromosomes without limit.
A natural question arises: how significant is the contribution of mobile elements to evolution? First, most of the transposable elements are introduced, roughly speaking, where they have to, as a result of which they can damage or change the structure or regulation of the gene into which they are introduced. Then natural selection sweeps aside unsuccessful options, and successful options with adaptive properties are fixed.

If the consequences of the introduction of a transposable element turn out to be neutral, then this variant can be preserved in the population, providing some diversity in the structure of the gene. This can come in handy under adverse conditions. Theoretically, during the mass movement of mobile elements, mutations can appear in many genes at the same time, which can be very useful in case of a sharp change in the conditions of existence.
So, to summarize: there are many mobile elements in the genome and they are different; they can interact both with each other and with the host genes; can be harmful and irreplaceable. The instability of the genome caused by the movement of mobile elements can end in tragedy for an individual, but the ability to change quickly is necessary condition survival of a population or species. This creates diversity, which is the basis for natural selection and subsequent evolutionary changes.
You can draw some analogy between jumping genes and immigrants: some immigrants or their descendants become equal citizens, others are given residence permits, and still others - those who do not comply with the laws - are deported or imprisoned. And mass migrations of peoples can quickly change the state itself.
Literature
Ratner V. A., Vasilyeva L. A. Induction of transpositions of mobile genetic elements by stressful influences. Russian binding. 2000.
Gvozdev V. A. Motile eukaryotic DNA // Soros Educational Journal. 1998. No. 8.
On 05/09/2011 at 09:36, Limarev said:
Limarev V.N.
Deciphering the human genome.
Fragment from the book by L.G. Puchko: "Radietic knowledge of man"
To solve the problems of deciphering the genome, the international project "Human Genome" was organized with a budget of billions of dollars.
By 2000, the map of the human genome was practically complete. Genes were counted, identified and recorded in databases. These are huge amounts of information.
Recording the human genome in digitized form takes about 300 terabytes of computer memory, which is equivalent to 3,000 hard drives with a capacity of 100 gigabytes.
It turned out. That a person does not have hundreds of thousands, as previously thought, but a little more than 30 thousand genes. The fly has Drosophila, there are only half as many of them - about 13 thousand, and the mouse has almost the same number as a person. Genes unique to humans in the decoded genome are only about 1%. Most of the DNA helix, as it turned out, is occupied not by genes, but by the so-called “empty sections”, in which genes are simply not encoded, as well as double fragments repeating one after another, the meaning and meaning of which is unclear.
In a word, genes turned out to be not even the bricks of life, but only elements of the blueprint, according to which the building of the organism is built. Bricks, as in other things it was believed before the heyday of genetics, are proteins.
It became absolutely obvious that in 1% of genes unique to humans, such a huge amount of information that distinguishes humans from mice cannot be encoded. Where is all the information stored? For many scientists, it becomes an undoubted fact that without the Divine principle it is impossible to explain the nature of man. A number of scientists suggest that, within the framework of existing ideas about the human body, it is basically impossible to decipher the human genome.
The world is not known - it is knowable (my comments on the article).
1) Consider the fragment: “Without the Divine principle, it is impossible to explain the nature of man.”
The above information does not say anything about this.
The genome, indeed, has a more complex structure than previously thought.
But, after all, the computer mentioned in the article does not consist only of memory cells.
A computer has two memories: long-term and operational, as well as a processor in which information is processed. Participates in the processing of information and the electromagnetic field. In order to decipher the information of the genome, it is necessary to understand how it happens, not only the storage of information, but also its processing. I also admit the idea that part of the information is stored recorded by means of an electromagnetic field. And also outside of a person, as I already wrote, in special information centers of the Higher Mind.
Imagine a continuous text encoded in binary code 0 or 1 of Morse code, while you do not know what language (English or French ....) it is written in, and you do not know that this continuous text consists of words, sentences, paragraphs, chapters, volumes, shelves, cabinets, etc.
It’s almost the same in biology, only everything is encoded here with a four-digit code and we have so far deciphered the order of elementary genes + - / *, but we don’t know the language and, accordingly words, sentences, paragraphs, chapters, volumes, shelves, cabinets, etc. The deciphered genome for us is still a solid text of a 4-cereal code and it is almost impossible to study it all head-on.
But it turns out that at certain times (both in an individual and his cohort of generations and in a species, genus), some genes and their complexes (responsible for words, sentences, paragraphs, chapters, volumes, shelves, cabinets, etc.) are active , and in other periods of evolution they are passive, which I indirectly determined by various polygenic traits (as shown in the topic Universal periodic law evolution).
So far, there are only two methods for studying genes, this is a simple laboratory calculation of the sum of genes (DNA) in a sample and there is a device that counts the amount of RNA produced by proteins stuck on the electronic chip generated specific DNA, but since a huge amount of DNA is active at every moment of time and, accordingly, a huge amount of different proteins are produced through RNA, it is very difficult to separate “this noodles with a spoon, fork and Japanese chopsticks” in this soup and find what you are looking for - to find causal relationships between a particular DNA (as a DNA complex) and its influence on a polygenic trait.
It seems that I have found a simple method of how to sort out this whole soup of DNA, RNA and their proteins that determine the degree of a polygenic trait.
As it turned out, each polygenic trait in the order of evolution of an individual (cohorts of generations, species and genus) is periodic, therefore, they must be periodic in RNA and DNA activity, and therefore it is only necessary to find (first going into genetic details) a correlation between the metric change in a polygenic trait (in an individual, a cohort of generations, a species, a genus...) and proportional to these periods, the corresponding activity of RNA, DNA.
Publishing house "BINOM. The Knowledge Lab publishes a book of memoirs by geneticist Craig Venter, Life Deciphered. Craig Venter is known for his work on reading and deciphering the human genome. In 1992, he founded the Institute for Genome Research (TIGR). In 2010, Venter created the world's first artificial organism, the synthetic bacterium Mycoplasma laboratorium. We invite you to read one of the chapters of the book, in which Craig Venter talks about the work of 1999-2000 on sequencing the Drosophila fly genome.
Forward and only forward
The fundamental aspects of heredity turned out, to our surprise, to be quite simple, and therefore there was a hope that, perhaps, nature is not so unknowable, and its more than once proclaimed by the most different people incomprehensibility is just another illusion, the fruit of our ignorance. This gives us optimism, because if the world were as complex as some of our friends claim, biology would have no chance of becoming an exact science.
Thomas Hunt Morgan. Physical foundations heredity
Many have asked me why, of all the living creatures on our planet, I chose Drosophila; others were interested in why I did not immediately move on to deciphering the human genome. The point is that we needed a basis for future experiments, we wanted to be sure that our method was correct before spending almost 100 million dollars on sequencing the human genome.
The little Drosophila has played a huge role in the development of biology, especially genetics. The genus Drosophila includes various flies - vinegar, wine, apple, grape, and fruit - in total about 26 hundred species. But it is worth saying the word "Drosophila", and any scientist will immediately think of one specific species - Drosophilamelanogaster. Because it reproduces quickly and easily, this tiny fly serves as a model organism for evolutionary biologists. They use it to shed light on the miracle of creation - from the moment of fertilization to the formation of an adult organism. Thanks to Drosophila, many discoveries have been made, including the discovery of homeobox-containing genes that regulate the general structure of all living organisms.
Every student of genetics is familiar with the Drosophila experiments performed by Thomas Hunt Morgan, the father of American genetics. In 1910, he noticed male mutants with white eyes among the usual red-eyed flies. He crossed a white-eyed male with a red-eyed female and discovered that their offspring turned out to be red-eyed: white-eyedness turned out to be a recessive trait, and now we know that for flies to have white eyes, two copies of the white-eyed gene are needed, one from each parent. Continuing to cross mutants, Morgan found that only males showed the trait of white eyes, and concluded that this trait was associated with the sex chromosome (Y chromosome). Morgan and his students studied heritable traits in thousands of fruit flies. Today, experiments with Drosophila are carried out in molecular biology laboratories around the world, where more than five thousand people study this small insect.
I'm on own experience realized the importance of Drosophila when he used libraries of its cDNA genes in the study of adrenaline receptors and discovered in the fly their equivalent - octopamine receptors. This discovery pointed to the commonality of the evolutionary heredity of the nervous system of the fly and the human. Trying to understand the cDNA libraries of the human brain, I found genes with similar functions by computer comparison of human genes with Drosophila genes.
The Drosophila gene sequencing project was launched in 1991 when Jerry Rubin of the University of California at Berkeley and Allen Spredling of the Carnegie Institution decided it was time to take on the task. In May 1998, 25% of the sequencing had already been completed, and I made a proposal that Rubin said was "too good to pass up." My idea was rather risky: thousands of fruit fly researchers from different countries we had to scrutinize each letter of the code we received, comparing it to Jerry's own high-quality, reference data, and then judge the suitability of my method.
The original plan was to complete the sequencing of the fly genome within six months, by April 1999, to then launch an attack on the human genome. It seemed to me that this was the most effective and understandable way for everyone to demonstrate that our new method works. And if we don’t succeed, I thought, then it’s better to be quickly convinced of this by the example of Drosophila than by working on the human genome. But, in truth, a complete failure would be the most impressive failure in the history of biology. Jerry was also risking his reputation, so everyone at Celera was determined to support him. I asked Mark Adams to lead our part of the project, and since Jerry also had a first-class team at Berkeley, our collaboration went like clockwork.
First of all, the question arose about the purity of the DNA that we had to sequence. Like humans, flies differ at the genetic level. If there is more than 2% genetic variation in a population, and we have 50 different individuals in the selected group, then deciphering is very difficult. First of all, Jerry had to inbreed the flies as much as possible to give us a homogenous version of the DNA. But inbreeding was not enough to ensure genetic purity: when extracting the fly's DNA, there was a danger of contamination with genetic material from bacterial cells found in the fly's food or in its intestines. To avoid these problems, Jerry preferred to extract DNA from mouse embryos. But even from the cells of the embryos, we had to first isolate the nuclei with the DNA we needed, so as not to contaminate it with the extranuclear DNA of the mitochondria - the "power plants" of the cell. As a result, we received a test tube with a cloudy solution of pure Drosophila DNA.
In the summer of 1998, Ham's team, with such pure fly DNA, set about creating libraries of fly fragments. Ham himself was most fond of cutting DNA and overlapping the resulting fragments, lowering the sensitivity of his hearing aid so that no extraneous sounds would distract him from his work. The creation of libraries was supposed to be the beginning of large-scale sequencing, but so far only the sounds of a drill, the sound of hammers and the squeal of saws were heard everywhere. A whole army of builders was constantly an eyesore nearby, and we continued to solve the most important problems - troubleshooting the operation of sequencers, robots and other equipment, trying not in years, but in a matter of months to create a real "factory" of sequencing from scratch.
The first Model 3700 DNA Sequencer was delivered to Celera on December 8, 1998, to great acclaim and a sigh of relief from everyone. The device was removed from a wooden box, placed in a windowless room in the basement - its temporary shelter, and immediately began trial testing. When it started working, we got very high quality results. But these first examples of sequencers were very unstable, and some were faulty from the very beginning. Problems constantly arose with the workers, sometimes almost daily. For example, a serious error appeared in the control program of a robotic arm - sometimes the robot's mechanical arm moved over the device at high speed and crashed into the wall with a swing. As a result, the sequencer stopped, and a repair team had to be called in to fix it. Some sequencers failed due to stray laser beams. To protect against overheating, foil and scotch tapes were used, since at high temperatures, dyed in sequences evaporated from yellow Gs fragments.
Although devices were now delivered regularly, about 90% of them were faulty from the start. Some days the sequencers didn't work at all. I was a firm believer in Mike Hunkapiller, but my faith was shattered when he blamed the failures of our employees, building dust, the slightest fluctuations in temperature, the phases of the moon, and so on. Some of us even turned gray from stress.
The lifeless 3700s, waiting to be sent back to ABI, stood in the cafeteria, and, in the end, it got to the point that we had to eat lunch in practically the “morgue” of sequencers. I was desperate - after all, I needed a certain number of working devices every day, namely 230! For about $70 million, ABI promised to provide us with either 230 perfectly functional devices that worked without interruption all day, or 460 that worked for at least half a day. In addition, Mike should have doubled the number of qualified technicians to repair the sequencers immediately after they break down.
However, what is the interest in doing all this for the same money! In addition, Mike has another client - a government genomic project, whose leaders have already begun to purchase hundreds of devices without any testing. The future of Celera depended on these sequencers, but Mike didn't seem to realize that the future of ABI depended on them as well. Conflict was inevitable, which was revealed at an important meeting of ABI engineers and my team held at Celera.
After we reported the sheer number of defective instruments and how long it took to fix broken sequencers, Mike again tried to put all the blame on my staff, but even his own engineers disagreed. Eventually Tony White intervened. "I don't care how much it costs or who needs to be nailed for it," he said. Then for the first and last time he really took my side. He ordered Mike to get the new sequencers shipped as soon as possible, even at the expense of other customers and even if it was not yet known how much it would cost.
Tony also directed Mike to hire twenty more technicians to quickly repair and determine the cause of any problems. In fact, this was easier said than done, because there were not enough experienced workers. To begin with, Eric Lander poached two of the most qualified engineers, and in Mike's opinion, we were also to blame for this. Turning to Mark Adams, Mike said, "You should have hired them before anyone else did." After such a statement, I finally lost all respect for him. After all, according to our contract, I could not hire ABI employees, while Lander and other heads of the state genome project had the right to do so, so very soon the best engineers from ABI began working for our competitors. By the end of the meeting, I realized that the problems remained, but a ray of hope for improvement still dawned.
And so it happened, although not immediately. Our arsenal of sequencers increased from 230 to 300 devices, and if 20-25% of them failed, we still had about 200 working sequencers and somehow coped with the tasks. The technicians worked heroically and steadily increased the pace of repair work, reducing downtime. All this time I was thinking about one thing: what we are doing is doable. Failures arose for a thousand reasons, but failure was not part of my plans.
We started sequencing the Drosophila genome in earnest on April 8th, around the time we should have completed this work. Of course, I understood that White wanted to get rid of me, but I did everything in my power to fulfill the main task. Tension and anxiety haunted me at home, but I could not discuss these problems with my “confidant” himself. Claire showed her contempt frankly, seeing how absorbed I was in Celera affairs. It seemed to her that I was repeating the same mistakes that I made when I worked at TIGR/HGS. By July 1, I felt deeply depressed, as I had already done in Vietnam.
Since the conveyor method did not work for us yet, we had to do hard exhausting work - to “glue” the genome fragments again. In order to detect matches and not be distracted by repetitions, Jean Myers proposed an algorithm based on the key principle of my version of the shotgun method: to sequence both ends of all resulting clones. Since Ham received clones of three precisely known sizes, we knew that the two terminal sequences were at a strictly defined distance from each other. As before, this way of "finding a pair" will give us an excellent opportunity to reassemble the genome.
But since each end of the sequence was sequenced separately, to ensure that this assembly method worked accurately, careful records had to be kept - to be absolutely sure that we were able to correctly connect all pairs of end sequences: after all, if even one in a hundred attempts results in an error and there is no corresponding pair for consistency, everything will go down the drain and the method will not work. One way to avoid this is to use a barcode and sensors to track every step of the process. But at the beginning of work, the laboratory assistants did not have the necessary software and sequencing equipment, so everything had to be done by hand. At Celera, a small team of less than twenty people processed every day record number clones - 200 thousand. We could anticipate some errors, such as misreading data from 384 wells, and then using a computer to find a clearly erroneous operation and correct the situation. Of course, there were still some shortcomings, but this only confirmed the skill of the team and the confidence that we can eliminate errors.
Despite all the difficulties, we were able to read 3156 million sequences in four months, a total of about 1.76 billion nucleotide pairs contained between the ends of 1.51 million DNA clones. Now it was the turn of Gene Myers, his team, and our computer to put all the pieces together into Drosophila chromosomes. The longer the sections became, the less accurate the sequencing turned out to be. In the case of Drosophila, the sequences averaged 551 base pairs and the average accuracy was 99.5%. Given 500-letter sequences, almost anyone can locate matches by moving one sequence along the other until a match is found.
For Haemophilus influenzae sequencing, we had 26,000 sequences. To compare each of them with all the others would require 26,000 squared comparisons, or 676 million. The Drosophila genome, with 3.156 million reads, would require about 9.9 trillion comparisons. In the case of humans and mice, where we performed 26 million reads of the sequence, about 680 trillion comparisons were required. Therefore, it is not surprising that most scientists were very skeptical about the possible success of this method.
Although Myers promised to fix everything, he constantly had doubts. Now he worked all day and all night, looked exhausted and somehow grayed out. In addition, he had problems in the family, and he began to spend most of his free time with the journalist James Shreve, who wrote about our project and followed the progress of research like a shadow. In an attempt to distract Gene somehow, I took him to the Caribbean with me to relax and sail on my yacht. But even there he sat for hours, hunched over his laptop, his black brows furrowed and his black eyes squinted against the bright sun. And, despite incredible difficulties, Gene and his team managed to generate more than half a million lines of computer code for the new assembler in six months.
If the sequencing results were 100% accurate, with no repetitive DNA, genome assembly would be a relatively easy task. But in reality, genomes contain a large amount of repetitive DNA. different type, different lengths and frequencies. Short repeats of less than five hundred base pairs are relatively easy to handle, longer repeats are more difficult. To solve this problem, we used the "finding a pair" method, that is, we sequenced both ends of each clone and obtained clones of different lengths to ensure the maximum number of matches.
The algorithms, encoded in Gene's team's half-million lines of computer code, involved a step-by-step scenario, from the most "harmless" actions, such as simply overlapping two sequences, to more complex ones, such as using discovered pairs to merge islands of overlapping sequences. It was like putting together a jigsaw puzzle, where the small islands of the collected plots are put together to form large islands, and then the whole process is repeated again. Only here in our puzzle there were 27 million pieces. And it was very important that the pieces come from a sequence of high build quality: imagine what happens if you put together a puzzle and the colors or images of its elements are fuzzy and blurry. For a long range order of the genome sequence, a significant proportion of reads should be in the form of matching pairs. Given that the results were still manually tracked, we were relieved to find that 70% of the sequences we had were exactly like this. Computer modeling specialists explained that with a smaller percentage, it would be impossible to collect our "humpty-dumpty".
And now we were able to use the Celera assembler to sequence the sequence: in the first step, the results were corrected to achieve the highest accuracy; in the second step, the Screener software removed the contaminating sequences from the plasmid or E. coli DNA. The assembly process can be disrupted by just some 10 base pairs of a “foreign” sequence. At the third stage, the Screener program checked each fragment against known repeat sequences in the fruit fly genome - data from Jerry Rubin, who "kindly" provided them to us. The location of repeats with partially overlapping regions was recorded. In the fourth step, another program (Overlapper) found the overlapping areas by comparing each fragment with all the others, a colossal experiment in processing a huge amount of numerical data. Every second, we compared 32 million fragments to find at least 40 overlapping base pairs with less than 6% difference. When two overlapping sections were found, we combined them into a larger fragment, the so-called "contig" - a set of overlapping fragments.
Ideally, this would be enough to assemble the genome. But we had to deal with stutters and repeats in the DNA code, which meant that one piece of DNA could overlap with several different regions, creating false connections. To simplify the task, we left only uniquely connected fragments, the so-called "unitigs". The program with which we performed this operation (Unitigger) essentially removed the entire DNA sequence that we could not determine with certainty, leaving only these unitigs. This step not only gave us the opportunity to consider other options for assembling fragments, but also greatly simplified the task. After the reduction, the number of overlapping fragments was reduced from 212 million to 3.1 million, and the problem was simplified by a factor of 68. Pieces of the puzzle gradually but steadily fell into place.
And then we could use the information about how the sequences of the same clone were paired, using the “framework” algorithm. All possible unitigs with mutually overlapping base pairs were combined into special scaffolds. To describe this stage in my lectures, I draw an analogy with the children's toy designer Tinkertoys. It consists of sticks of different lengths, which can be inserted into holes located on wooden key parts (balls and disks), and thus make up a three-dimensional structure. In our case, the key parts are unitigs. Knowing that paired sequences are located at the ends of clones 2,000, 10,000 or 50,000 base pairs long - that is, as if they are at a distance of a certain number of holes from each other - they can be lined up.
Testing this technique on the Jerry Rubin sequence, which is about one-fifth of the fruit fly genome, resulted in only 500 gaps. After running tests on our own data in August, we got more than 800,000 small fragments as a result. A significantly larger amount of data for processing showed that the technique worked poorly - the result was the opposite of what was expected. Over the next few days, panic escalated, and the list possible errors lengthened. From the top floor of building No. 2, an adrenaline rush leaked into the room, jokingly called "Serene quarters." However, there was no peace and serenity there, especially for at least a couple of weeks, when employees literally wandered around in circles in search of a way out of this situation.
In the end, the problem was solved by Arthur Delcher, who worked with the Overlapper program. He noticed something odd about line 678 of the 150,000 lines of code, where a trivial inaccuracy meant that an important part of the match had not been recorded. The error was corrected and on September 7th we had 134 cell scaffolds covering the active (euchromatic) fruit fly genome. We were delighted and breathed a sigh of relief. It's time to announce our success to the world.
The Genome Sequencing Conference, which I started a few years ago, provided a great opportunity for this. I was sure there would be a large number of people eager to see if we kept our promise. I decided that Mark Adams, Jean Myers and Jerry Rubin should talk about our achievements, and above all about the sequencing process, the assembly of the genome and the significance of this for science. Due to the influx of people who wanted to come to the conference, I had to move it from Hilton Head to the larger Hotel Fontainebleau in Miami. The conference was attended by representatives of major pharmaceutical and biotech companies, experts in genomic research from around the world, quite a few columnists, reporters and representatives of investment companies - all were assembled. Our competitors from Incyte spent a lot of money on organizing a reception after the end of the conference, corporate video filming and so on - they did everything to convince the public that they offer "the most detailed information about the human genome."
We gathered in a large conference room. Designed in neutral colors, decorated with wall lamps, it was designed for two thousand people, but the people kept coming, and soon the hall was filled to overflowing. The conference opened on September 17, 1999, and Jerry, Mark and Gene made presentations at the first session. After a short introduction, Jerry Rubin announced that the audience was about to hear about the best collaborative project of famous companies in which he had ever had the opportunity to participate. The atmosphere heated up. The audience realized that he would not have spoken so pompously if we had not prepared something really sensational.
In the ensuing silence, Mark Adams began to describe in detail the work of our “factory floor” at Celera and our new methods for genome sequencing. However, he did not say a word about the assembled genome, as if teasing the public. Then Jin came out and talked about the principles of the shotgun method, about Haemophilus sequencing, about the main stages of assembly work. Using computer animation, he demonstrated the entire process of reassembling the genome. The time allotted for presentations was running out, and many had already decided that everything would be limited to an elementary presentation using the PowerPoint program, without presenting concrete results. But then Jin remarked with a sly smile that the audience would probably still want to see the real results and would not be satisfied with imitation.
It was impossible to present our results more clearly and expressively than Gene Myers did. He realized that the results of sequencing alone would not make the right impression, so for greater persuasiveness he compared them with the results of Jerry's painstaking study using the traditional method. They turned out to be identical! Thus, Jean compared the results of our genome assembly with all known markers mapped on the fruit fly genome decades ago. Of the thousands of markers, only six did not match the results of our assembly. By carefully examining all six, we were convinced that Celera's sequencing was correct and that errors were contained in works performed in other laboratories with older methods. In the end, Gene said that we had just started sequencing human DNA, and there would probably be less problems with repetitions than in the case of Drosophila.
Loud and prolonged applause followed. The rumble that did not stop even during the break meant that we had achieved our goal. One of the journalists noticed a participant in the state genome project shaking his head in dismay: “It looks like these bastards are really going to do everything” 1 . We left the conference with renewed energy.
It remains to decide two important issues and both were well known to us. The first is how to publish the results. Despite a memorandum of understanding signed with Jerry Rubin, our business team did not approve of the idea of submitting valuable Drosophila sequencing results to GenBank. They suggested placing the results of fruit fly sequencing in a separate database at the National Center for Biotechnology Information, where they could be used by everyone on one condition - not for commercial purposes. Hot-tempered, constantly smoking Michael Ashburner of the European Institute of Bioinformatics was extremely unhappy with this. He felt that Celera had “conned everyone” 2 . (He wrote to Rubin: "What the hell is going on in Celera?" 3) Collins was also unhappy, but more importantly, Jerry Rubin was also unhappy. In the end, I did submit our results to GenBank.
The second problem concerned Drosophila - we had the results of sequencing its genome, but we did not understand at all what they meant. We had to analyze them if we wanted to write an article - just like four years ago in the case of Haemophilus. The analysis and description of the fly genome could take more than a year - and I did not have such time, because now I had to focus on the human genome. After discussing this with Jerry and Mark, we decided to involve the scientific community in working on Drosophila, turning it into an exciting scientific task, and thus quickly move the matter, turn the boring process of describing the genome into a fun holiday - like an international scouting gathering. We called it the "Genomic Jamboree" and invited leading scientists from all over the world to come to Rockville for about a week or ten days to analyze the fly's genome. Based on the results obtained, we planned to write a series of articles.
Everyone liked the idea. Jerry began sending invitations to our event to groups of leading researchers, and Celera's bioinformatics experts decided what computers and programs would be needed to make the scientists' work as efficient as possible. We agreed that Celera would pay for their travel and accommodation expenses. Among those invited were my harshest critics, but we hoped that their political ambitions would not affect the success of our undertaking.
In November, about 40 Drosophila specialists arrived, and even for our enemies, the offer turned out to be too attractive to refuse it. In the beginning, when the participants realized that they would have to analyze more than one hundred million base pairs of the genetic code within a few days, the situation was quite tense. While the newly arrived scientists slept, my employees worked around the clock, developing programs to solve unforeseen problems. By the end of the third day, when it turned out that new software tools allow scientists, as one of our guests said, “to make amazing discoveries in a few hours, which used to take almost a lifetime,” the atmosphere was calmed down. Every day in the middle of the day, at the signal of the Chinese gong, everyone gathered together to discuss the latest results, solve current problems and draw up a work plan for the next round.
Every day the discussions became more and more interesting. Thanks to Celera, our guests have the opportunity to be the first to look into new world, and what was revealed to the eye, exceeded expectations. It soon turned out that we did not have enough time to discuss everything we wanted to and understand what it all meant. Mark hosted a celebratory dinner that didn't last very long as everyone quickly rushed back to the labs. Soon lunches and dinners were consumed right in front of computer screens with data on the Drosophila genome displayed on them. Long-awaited families of receptor genes have been discovered for the first time, and at the same time a surprising number of fruit fly genes similar to human disease genes have been discovered. Each opening was accompanied by joyful cries, whistles and friendly pats on the shoulder. Surprisingly, in the midst of our scientific feast, one couple found time to get engaged.
True, there was some concern: in the course of the work, scientists discovered only about 13 thousand genes instead of the expected 20 thousand. Since the “lowly” worm C. elegans has about 20 thousand genes, many believed that the fruit fly should have more of them, since it has 10 times more cells and even has a nervous system. There was one simple way to make sure that there was no error in the calculations: take the 2500 known fly genes and see how many of them could be found in our sequence. After careful analysis, Michael Cherry of Stanford University reported that he had found all but six of the genes. After discussion, these six genes were classified as artifacts. The fact that the genes were identified without errors encouraged us and gave us confidence. A community of thousands of scientists dedicated to Drosophila research had spent decades tracking those 2,500 genes, and now as many as 13,600 were in front of them on a computer screen.
During the inevitable photo shoot at the end of the job, there was an unforgettable moment: after the traditional pat on the shoulder and friendly handshakes, Mike Ashburner got down on all fours for me to immortalize himself in the photo with a foot on his back. So he wanted - despite all his doubts and skepticism - to pay tribute to our achievements. A well-known geneticist, Drosophila researcher, he even came up with an appropriate caption for the photo: "Standing on the shoulders of a giant." (He had a rather frail figure.) "Let's give credit to the one who deserves it," he wrote later 4 . Our opponents tried to present the lapses in the transfer of sequencing results to a public database as a deviation from our promises, but they, too, were forced to admit that the meeting made an "extremely valuable contribution to the worldwide research of the fruit fly" 5 . Having experienced what a genuine "scientific nirvana" is, everyone parted as friends.
We decided to publish three large papers: one on whole genome sequencing with Mike as first author, another on genome assembly with Gene as first author, and a third on comparative worm, yeast and human genome genomics with Jerry as first author. The papers were submitted to Science in February 2000 and published in a special issue dated March 24, 2000, less than a year after my conversation with Jerry Rubin in Cold Spring Harbor. 6 Prior to publication, Jerry arranged for me to speak at the annual Drosophila Research Conference in Pittsburgh, which was attended by hundreds of the most prominent experts in the field. On each chair in the hall, my staff placed a CD containing the entire Drosophila genome, as well as reprints of our articles published in Science. Jerry introduced me very warmly, assuring the audience that I had fulfilled all my obligations and that we had worked very well together. My presentation ended with a report on some of the research done during the meeting, and brief comments to the data on the CD. The applause after my talk was just as surprised and enjoyable as it was when Ham and I first presented the Haemophilus genome at the microbiology convention five years ago. Subsequently, papers on the Drosophila genome became the most frequently cited papers in the history of science.
While thousands of fruit fly researchers around the world were thrilled by the results, my critics quickly went on the offensive. John Sulston called the attempt to sequence the fly's genome a failure, even though the sequence we obtained was more complete and more accurate than the result of his painstaking decade of sequencing the worm's genome, which took another four years to complete after the draft was published in Science. Salston's colleague Maynard Olson called the Drosophila genome sequence "an outrage" that, "by the grace" of Celera, participants in the state human genome project will have to deal with. In fact, Jerry Rubin's team was able to quickly close the remaining gaps in the sequence by publishing and comparing the already sequenced genome in less than two years. These data confirmed that we made 1–2 errors per 10 kb in the entire genome and less than 1 error per 50 kb in the working (euchromatic) genome.
However, despite the general acceptance of the Drosophila project, in the summer of 1999, tensions in my relationship with Tony White came to a head. White could not reconcile with the attention that the press paid to me. Every time he came to Celera, he passed copies of articles about our achievements hung on the walls in the hallway next to my office. And here we zoomed in on one of them, the cover of the USA Today Sunday supplement. On it, under the heading “Will this ADVENTURER achieve the greatest scientific discovery our time?" Figure 7 showed me, in a blue plaid shirt, with my legs crossed, and Copernicus, Galileo, Newton and Einstein were floating in the air around me - and no sign of White.
Every day, his press secretary called to see if Tony could take part in the seemingly endless stream of interviews going on at Celera. He calmed down a little, and then only briefly, when the following year she managed to get his photo placed on the cover of Forbes magazine as the man who was able to increase the capitalization of PerkinElmer from $1.5 billion to $24 billion 8 . (“Tony White turned poor PerkinElmer into a high-tech gene-catcher.”) Tony was haunted by my social activism as well.
About once a week I gave a talk, agreeing to a small fraction of the huge number of invitations that I constantly received because the world wanted to know about our work. Tony even complained to the board of directors of PerkinElmer, by then renamed PE Corporation, that my travels and performances violated corporate rules. During a two-week vacation (at my own expense) I spent at my home on Cape Cod, Tony, along with CFO Dennis Winger and Applera General Counsel William Souch, flew to Celera to debrief my senior staff about "the effectiveness of Venter's leadership." They hoped to collect enough dirt to justify my dismissal. White was amazed when everyone said that if I left, they would also quit. This caused a lot of tension in our team, but at the same time brought us closer together than ever. We were ready to celebrate every victory as if it were our last.
After the publication of the fly's genome sequence - by then the largest sequence ever deciphered - Gene, Ham, Mark and I toasted to having endured Tony White long enough to have our success recognized. We have proven that our method will also work in human genome sequencing. Even if the next day Tony White stopped funding, we knew that our main achievement would remain with us. More than anything, I wanted to get away from Celera and not associate with Tony White, but more than that, I wanted to sequence the genome Homo sapiens I had to compromise. I tried my best to please White, just to continue the work and complete my plan.
Notes
1. Shreeve J. The Genome War: How Craig Venter Tried to Capture the Code of Life and Save the World (New York: Ballantine, 2005), p. 285.
2. Ashburner M. Won for All: How the Drosophila Genome Was Sequenced (Cold Spring Harbor Laboratory Press, 2006), p. 45.
3. Shreeve J. The Genome War, p. 300.
4. Ashburner M. Won for All, p. 55.
5. Sulston J., Ferry G. The Common Thread (London: Corgi, 2003), p. 232.
6. Adams M. D., Celniker S. E. et al. "The Genome Sequence of Drosophila Melanogaster", Science, no. 287, 2185–95, March 24, 2000.
7. Gillis J. “Will this MAVERICK Unlock the Greatest Scientific Discovery of His Age? Copernicus, Newton, Einstein and VENTER?”, USA Weekend, January 29–31, 1999.
8. Ross P. E. "Gene Machine", Forbes, February 21, 2000.
Craig Venter